파이썬 스크래핑 크롤링 csv 형태로 정리 방법 bs4 사용법
안녕하세요 오늘은 파이썬 스크래핑 하여 csv 파일로 정리해 보려고 합니다
나도 코딩님의 강의를 보고 다음에 다시 생각 안 날 때 잠깐 봐야지라는 생각으로
정리하였습니다.
일단 파이썬 모듈을 다운로드해야 합니다
python 에디터 cmd 에 가세 pip install requests를 적어 다운로드를 해줍니다
저는 비주얼 스튜디오를 사용해서 다운로드했습니다.

이렇게 되면 python에서 requests 모듈을 다운로드한 것인데요
사실 웹스크래핑 과 크롤링 은 매우 쉽습니다 그리고 python 은 학자들이 실험
하기 위에 만든 것이라 웹 스크래핑 크롤링은 엄청 쉬운데요.
이제 방법을 알아보겠습니다
1. python requests 모듈 import 하기
가장 먼저 파이썬에서 모듈을 import 해줍니다
import requests

사실 이렇게 하면 스크래핑을 다한 것입니다 저희가 모르는 방식으로 requests 모듈
에는 전부돼있거든요 ㅎㅎ
2. python requests 모듈을 이용해서 페이지 정보 가져오기
res = requests.get('https://google.com')

변수 하나를 선언해 준 후에 자기가 스크래핑 하고 싶은 저는 아주 기본적인 웹페이지
인 구글 정보를 넣어줬습니다 가져오고 싶은데 웹페이지 정보를 넣어주시면 됩니다
status_code는 웹사이트 정보를 코드로 정렬할 것입니다
200 : 웹페이지 가져오기 성공 400 : 웹페이지 문제 500: 서버 문제라고 간단하게 생각하시면 됩니다
이렇게 해서 가져오고 싶은 웹페이지를 넣어준 후에 print(res.status_code)
를 해준 후 200 번이 나왔으면 그 웹페이지를 가져오기 성공한 것입니다
3. python bs4 패키지의 BeautifulSoup 모듈 가져오기
아까 위에서 했던 방법처럼 pip install beautifulsoup4 이라고 cmd 창에
눌러 BeautifulSoup 모듈을 다운로드합니다

그 후 from bs4 import BeautifulSoup
맨 위에 해줍니다

4. python BeautifulSoup 객체 만들기
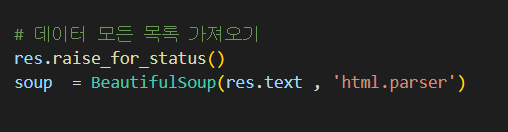
위에 res = requests.get('https://google.com')
res.raise_for_status()
soup = BeautifulSoup(res.text , 'html.parser')
ㄱ했던 객체를 이용해서 text를 가져와 준후 옆에 html.parser를 적어줍니다
사실 이렇게 되면 아주 작은 기본 운동을 끝났다고 보시면 됩니다 이게 왜 이렇지?
라고 생각하셨다면 bs4 와 requests 모듈 안에 저희가 모르는 어떠한 내부 구현으로
돼있기 때문에 여기까지는 필수라고 보시면 됩니다
5. python BeautufulSoup를 이용해서 가져오고 싶은 데이터 스크레핑 하기
사실 이 부분은 사람마다 가져오고 싶은 데이터 가 다르기에 방법만 알려드리겠습니다 하지만 이 방법만 듣고도 충분히 하실 수 있으리라 믿습니다
cartoons = soup.find_all( '가져오고싶은 태그 ' , attrs={'html 의 class또는 name 또는 id':'그에맞는 이름 '})
이렇게 하여 Html 문서안에 가져오고싶은데이터와 가져오고싶은것의 이름이
class인가 또는 아이디 인가 를 구분해서 적어준다음에 class이름id 이름 그에맞는
이름을 적어주면 정보를 가져오는것을 알수있습니다
이렇게 간단하게 웹스크래핑 하는 방법은 매우 쉬운데요 이렇게하여 가져오고 싶은 정보를 가져올수있습니다 python 의 bs4 모듈로 하는것은 동적인 페이지를 가져오지못합니다 그래서 다른 모듈이있는데 다음에는 그 모듈을 포스팅 하겠습니다 감사합니다
누군가에 도움이되었다면 공감한번눌러주세요 !!